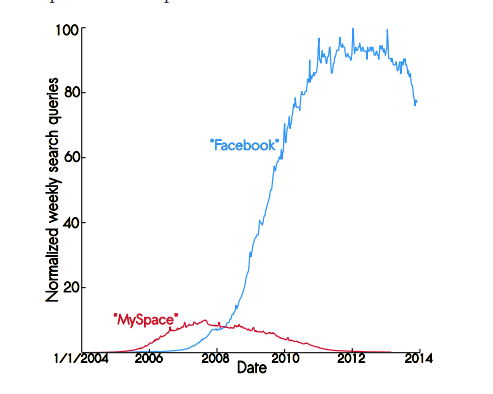
There is a lot of fuss these days because of the newest announcement made by Twitter on February 5. They encourage research institutions to apply until March 15 in what seem to be a scientific lottery, for a chance to the access of twitter’s data sets. Around 500 million Tweets are sent out each day and if they were to be scientifically quantified, studies like where the flu may hit, health-related information or events like ringing in the new year could be analyzed from a statistical point of view and outcomes could be predicted.
Twitter acknowledges the difficulties that researchers have to face when they have to collect data from the platform and therefore it named this project the Twitter Data Grants, aiming for a better connection between research institutions or academics and the data they need. Also, along with the data itself, the company will offer for the selected institutions the possibility of collaboration with their own engineers and researchers, all this, with the help of Gnip one of the most important Twitter’s certified data reseller partner.