Recently we have tested a Data Mining tool about which i want to write today. It is called Datameer and it’s a cloud app based on Hadoop so we don’t need to install anything on our computers but we must have the data that we want analyzed.
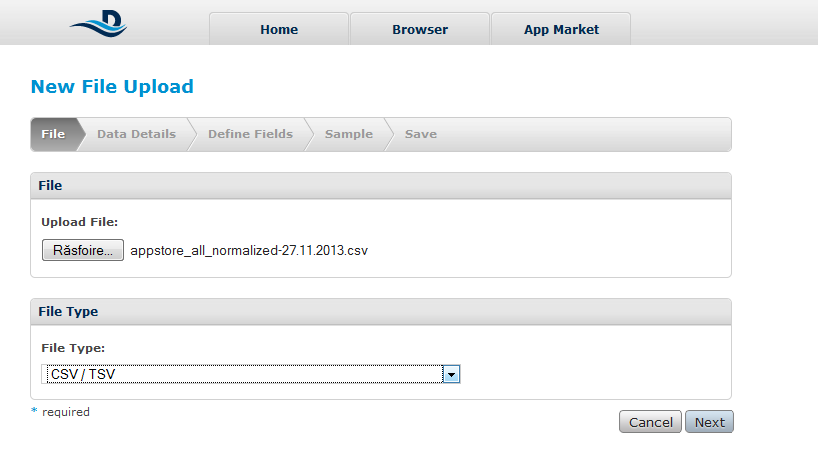
Step 1: Importing the data
To import any kind of data we must select the format of them:
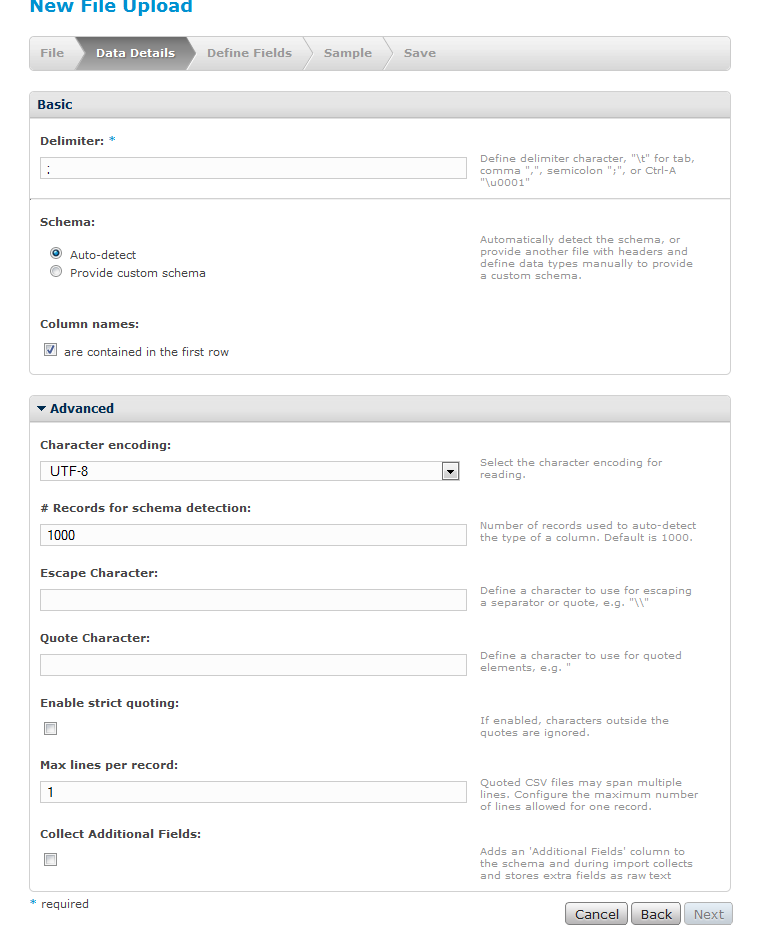
Step 2: A small configuration
Some of which regard data format, others of the way to detect certain data types. This program tries to detect each column’s type being possible to add data types from a file:
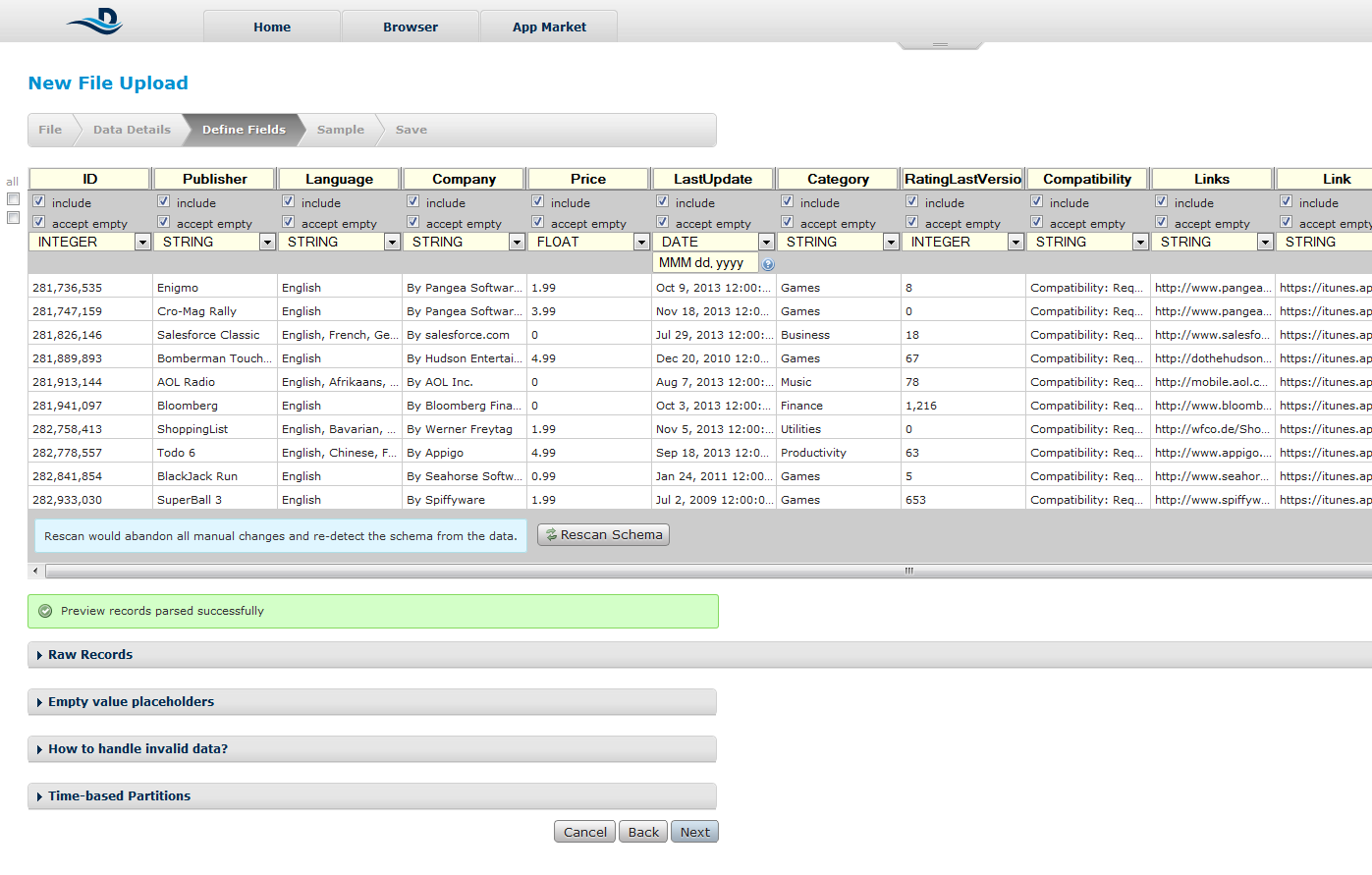
Step 3: Some fine adjustments
If the program doesn’t detect the columns well we can do it manually. A bad of this program is the fact that we can adjust data at this step only by removing of the recordings that won’t correspond to the type of data recently defined.
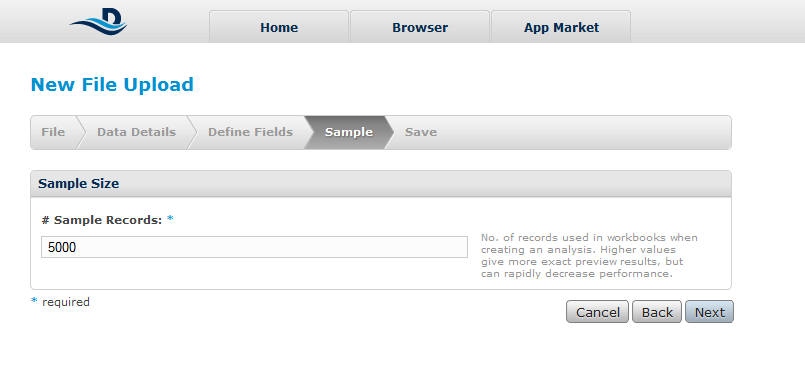
Step 4:Selecting the sample used for previsualisation
So this is all it is to be done for adding data into Datameer. Further on, an excel-like interface shows all the data .
Here we can find a few buttons responsible for the magic:
Column Dependency
Shows the relation between different columns and basically if a variable depend on other.
Clustering
Using this we can group similar data.
All the discovering part is done by the program and we only have to specify the number of clusters that we want.
Decision Tree
Builds a decision tree based on the data.
These are all the important function of Datameer, but the true importance of this App relies not on the functions but on the ability of processing a huge quantity of data/
 Most of the data we deliver is CSV type (comma separated values). Each row represents a value, and also different proprieties of a value are, you guessed it, comma separated. Of course that in order for this to have any meaning the order of this proprieties is kept for each row(each value).
Most of the data we deliver is CSV type (comma separated values). Each row represents a value, and also different proprieties of a value are, you guessed it, comma separated. Of course that in order for this to have any meaning the order of this proprieties is kept for each row(each value).