There comes a time in each of our lives when we wonder ourselves either from curiosity or from perspective what is going to be the next big thing, and because this is a blog dedicated to science we are gonna restrict to this area.
Of course we can’t know what is going to be the technology of tomorrow but we are going to tell you what is not going to be: Facebook! According to Princeton’s engineers facebook it’s very likely to reach to an end in the next few years. They used for the research an epidemiological model, very similar to Gaussian bell but more complex in the way of describing the transmission of communicable disease through individuals. According to the model chosen, called SIR the total number of population equals the sum of Susceptible plus Infected plus Recovered persons. They chose this pattern because is relevant for phenomena with relative short life span, and after that they applied in the case of MySpace and they noticed that it fit almost perfectly.
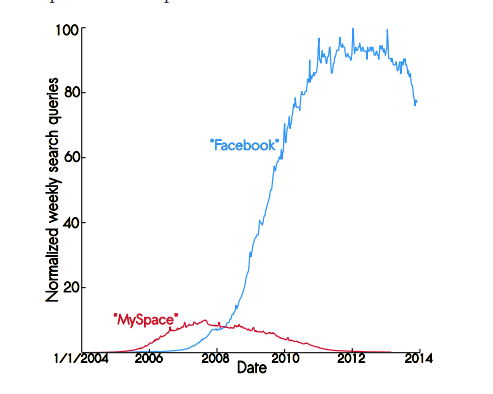
We can easily see in this graph that the decline of facebook has already begun but it’s not as near as expected. Actually we can be sure that we will not exterminate it from our lives sooner than 2018 but also, internet can be a very unpredictable place and no one can exactly determine how it’s going to end.
Also we advise you not to take for granted this study because, as we found out, it was conducted by researchers based in the school’s department of mechanical and aerospace engineering. Not saying that they are not professionals but nevertheless not experts in such social studies.