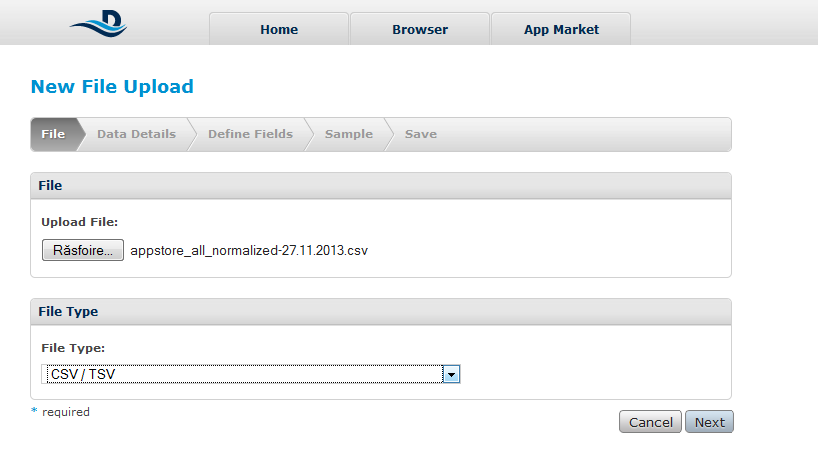
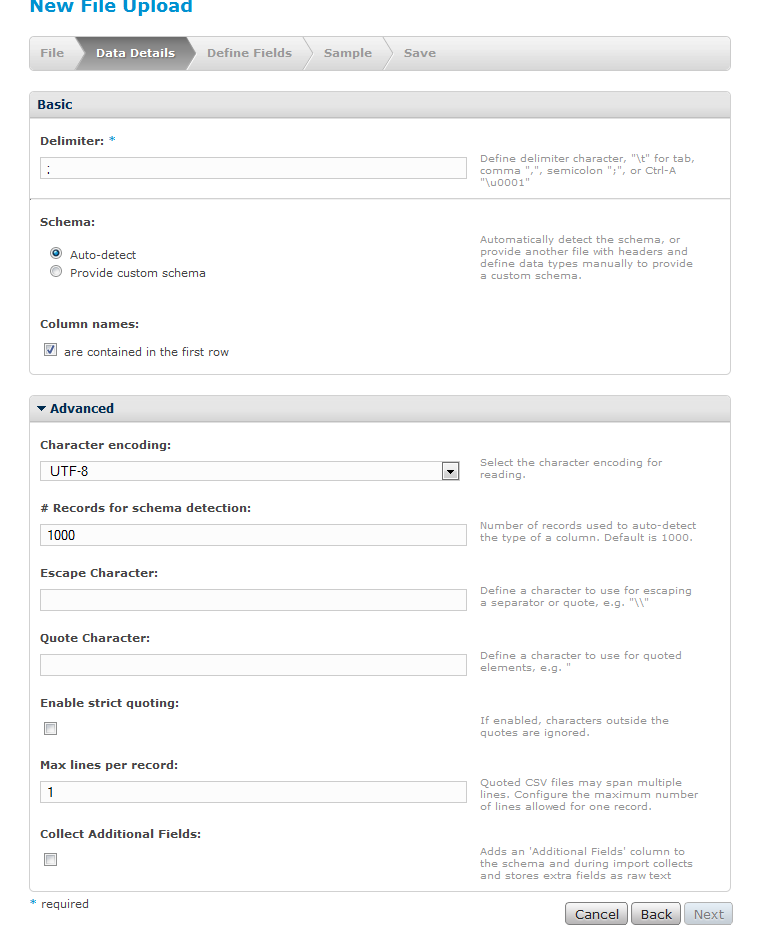
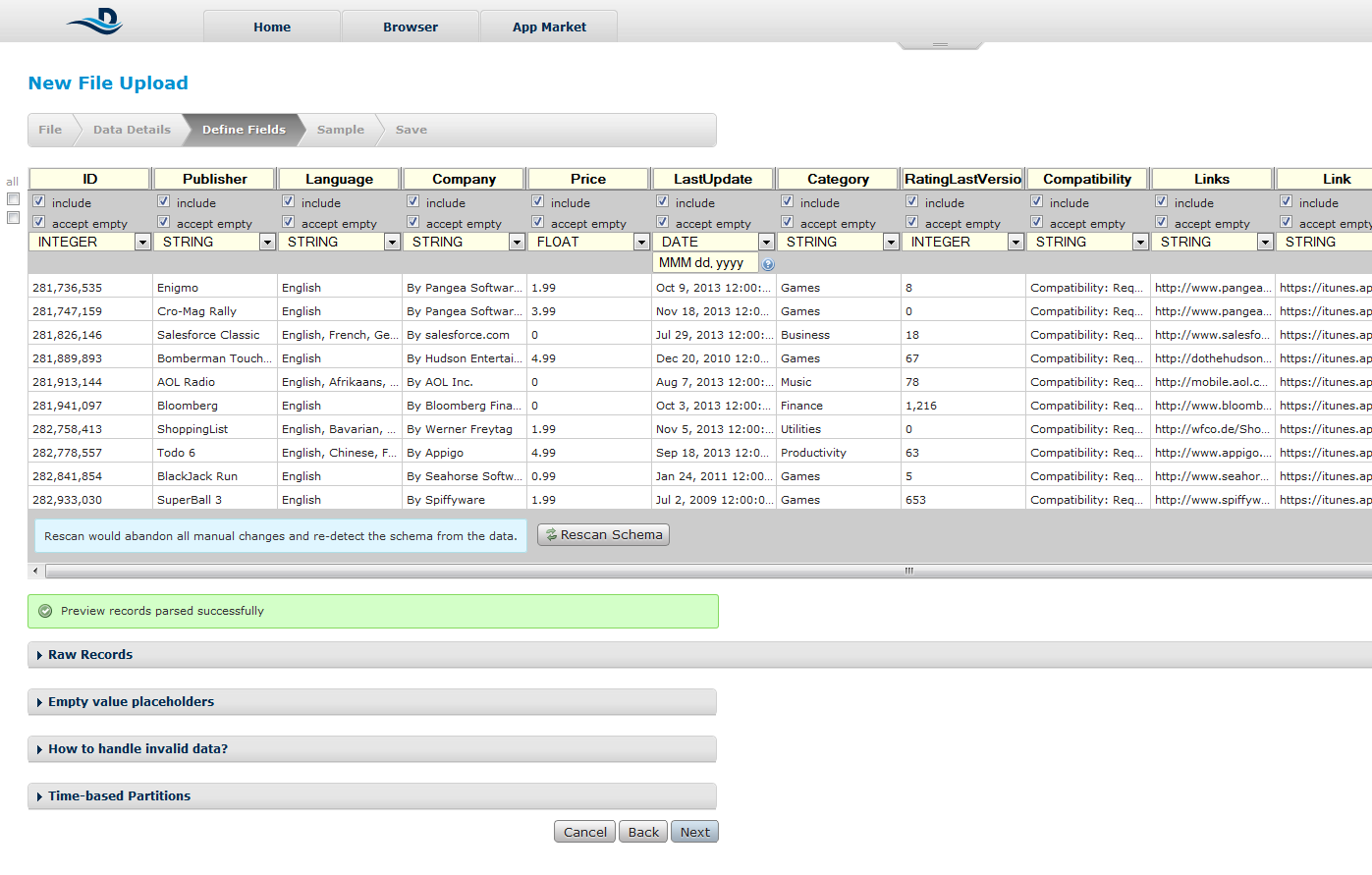
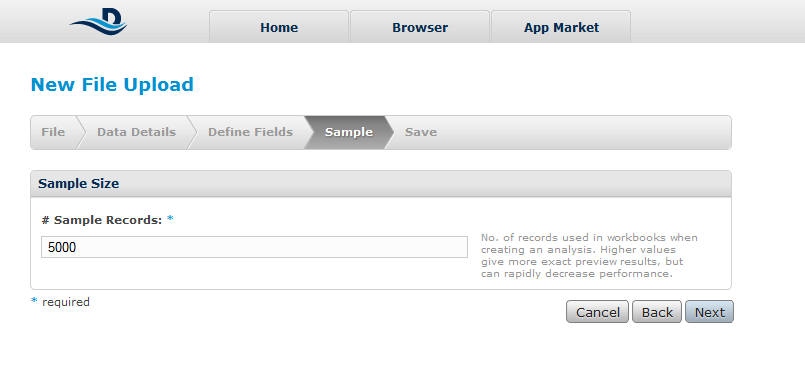
Microformats are small patterns that can be embedded into your HTML for easier recognition and representation of common published materials, like people, events, dates or tags. Even though the content of web is fully capable of automated processing, microformats simplify the process by attaching semantics and other so lead the way for a more professional automated processing. Many advantages can be found in favor of microformats but the most crucial are these ones.
By this time i should mention that microformats are a huge relief in web scraping by defining lightweight standards for declaring info in any web page. By doing so another concept of HTML5 is defined, Microdata. This lets you define custom variables and implement certain proprieties of them.
Now that you know what microformats are we should focus on the getting started part. A really useful, quick and detailed guide can be found here, and more complex task are also available. Now, the only thing left is to wish you good luck into implementing it .