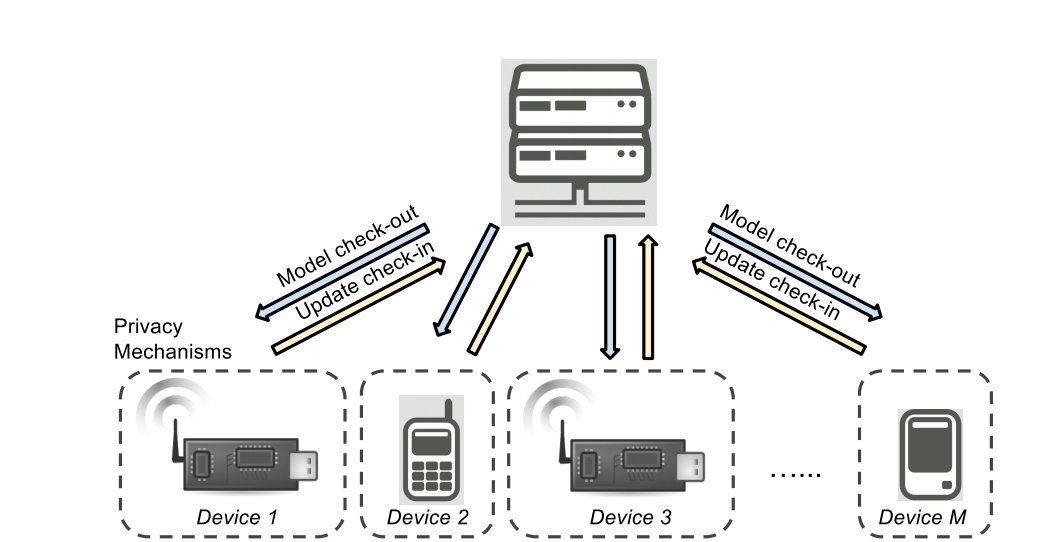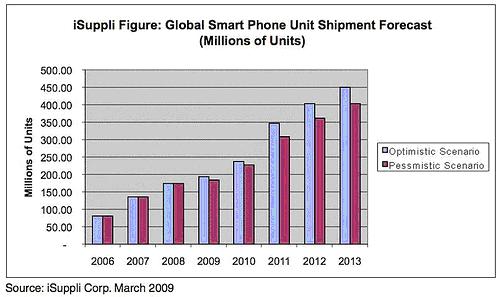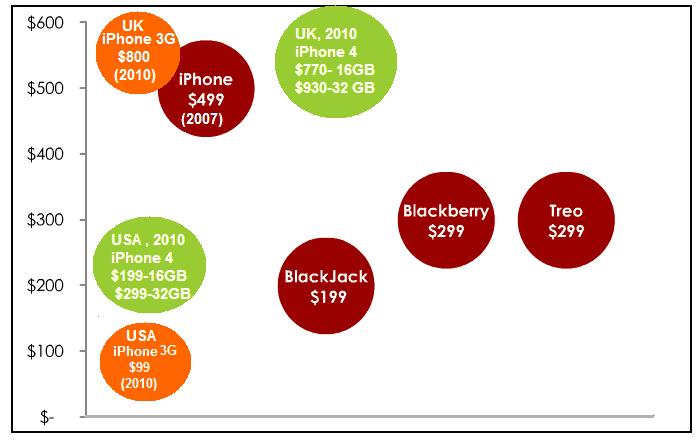
Data science can be a art, a art of identifying patterns and decisions before of even being taken, all this, with impressive accuracy. For our blog’s comeback I thought I should cover more the literary part of this science-art-craft and talk about some of the ground principles exposed in some of the finest books about data science.
In today’s article I will focus on a very well sturctured paper of Trevor Hastie, Professor of Mathematical Sciences at Stanford Univesity. His book, co-writed with Robert Tibshirani and Jerome Friedman is called The Elements of Statistical Learning: Data Mining, Inference, and Prediction and tries, if not, manages to give a detailed explanation to the challenge of understanding of how data led to development of new tools in the field of statistics, and spawned new areas such as data mining, machine learning, and bioinformatics. This paper mainly observes the important fields and ideas in a common virtual framework.

The approach being mainly is statistical, the emphasis falls on concepts rather than on mathematics. Many examples are given, with a easy-to-understand use of color graphics. It is a valuable resource for statisticians and everyone interested in data mining in science or industry. The book’s coverage is broad, from supervised learning (better known as prediction) to unsupervised learning. Various topics are covered including neural networks, support vector machines, classification trees and boosting – the first comprehensive treatment of this topic in any book of this kind.
All in all I can certainly say that the presentation is not keened on mathematical aspects, and it does not provide a deep analysis of why a specific method works. Instead, it gives you some intuition about what a method is trying to do. And this is the reason why i can say that I like this book so much. Without going into mathematical details of complicated algorithms, it summarizes all necessary (and really important) things one needs to know. Sometimes you understand it after doing a lot of research in this subject and coming back to the book. Nevertheless, the authors are great statisticians and certainly know what they are talking about!