
Sooner we have worked at a project with restaurants and other public locations. And for this we needed an estimation of number of all the restaurants and other public locations as pubs and cafes. Continue reading
Sooner we have worked at a project with restaurants and other public locations. And for this we needed an estimation of number of all the restaurants and other public locations as pubs and cafes. Continue reading

restaurant list
This post is headed to our american public because it features our sale for the complete list of Restaurants from United States. These were extracted from a trusted source and are up to this date.
Either if you work in food industry and want to set up a data base of potential customers nearby or just data enthusiast, this list will meet your requirements, providing not only address but also a telephone number for the available locations.
This list can be used also in many market researches as density of restaurants for a place or a town to detect where is a right position to build your restaurant, or just to make some marketing campaign if your product it’s for restaurants, pubs, coffee or other public locations.
Also, a sample of the file can be found here so you can check before buying, and for any further questions we are available through our contact form.
The US restaurants list is available along with more information at this link. Have a nice week!
These days I have published a Python 3 module intense used at TheWebMiner. The module it’s called PyTor and it’s available here: https://github.com/adibalcan/PyTor. It helps us to avoid CAPTCHA or other mechanisms for blocking the robots that crawl fast, websites. With this module you can detect when a website ban your IP address and you can easily change it (actually this happens automatically). Now this module it’s public and you can use it in your application.
I hope that it’s useful for you.
It’s been a while since our last post and lots of things happened in The Web Miner secret workshop so, be ready for we are about to launch a tool that should not be missed by no serious marketing department.
The problem we are trying to solve is the fast access to information that is needed to take a decision regarding the course of prices of a whole ecommerce. Just as it is said in entrepreneurship, if you heard it, it’s already to late to start a business with it, we can transcript that for those who set up the price policy of any store. They need to be in contact with the market without a break and to be aware that even for a slight change of their prices the sales could go up and down at an astonishing rate, because in the end if we neglect the rate of trust of users for certain sites or other facilities regarding shipping, all online shops are the same for final consumers.
How was this solved in the past is simple: it was not! Mainly because people were not aware of the advantages that a quick response rate to changes can give to a shop. Also before 2010 the competition between online businesses was not that high so this didn’t became a problem until rather recently.
A thought for the end is that the market will never finish evolving and that ecommerce shops haven’t reached the peak yet, and so, new rules are being added to this industry so better be aware. After all, better safe than sorry!
We often run multiple task on the same server… and while ago we have used screening to manage multiple tasks/screens on server. Now we use Byobu because it’s simple to use. With Byobu the challenge is to setup function keys to work with your windows SSH client. After we try many ssh clients and many setups we discovered a perfect match between MTPuTTY ( who usees PuTTY ) and Byobu.
How to setup PuTTY to work well with Byobu:
Setup Keyboard in PuTTY config:
Terminal -> Keyboard -> The Function keys and keypad -> SELECT Xterm R6
Setup PuTTY connection:
Connection -> Data -> SET Terminal-type string AS xterm
This is all 🙂
I hope that is useful for you and you can avoid complications.
For those of you who aren’t convinced yet that Big Data infiltrates more and more in our daily lives i have one more proof that data science is the future of all sciences and has the power of interconnecting all branches of life. it’s not a fast process, replacing conventional methods of taking decisions with ones more analytically but certainly the small steps we are taking are headed in that direction.

Although the improvement was of only 12% Los Angeles took a giant leap last week when they announced that after a effort of more than 30 years of local authorities they managed to synchronize and adapt to traffic conditions all the red light signals in the 4 millions residents city, making this an experiment we will all have something too learn in the near future.
Research engineers in state DOT explained that synchronizing traffic light is only a small step in decongesting the traffic and this is why they are more focused on studying the habit of the drivers. Since the ’80s they anonymously gathered data, first through a network of cables and sensors placed into the roads, called loop wires and more recently, as the technology evolved, they used toll bots to calculate average speed of cars or wireless sensors to detect number of people in the car, by the number of phones inside and their behaviors.
The next step, traffic researchers say will be to find a way to communicate with the car itself for gathering of data and ultimately to provide real time feedback for congested streets, alternative routes or energy management tips. Last but not least, improving public transportation must be a priority in every form it can be found, and also implementing new ways like modular self driving cars, linked together for a common road portion, all for better management of transportation.
I want to write now about a phenomena that is a part of our lives with or without our consent. I’m talking about Apple’s market strategy and how its intrusive policy of becoming one of the most exquisite brands have affected our perception on quality or innovation.
There’s no point in denying the direct correlation between Apple total revenue and the influence it has on the market of electronics and only by looking at the graph of sales we can say so. 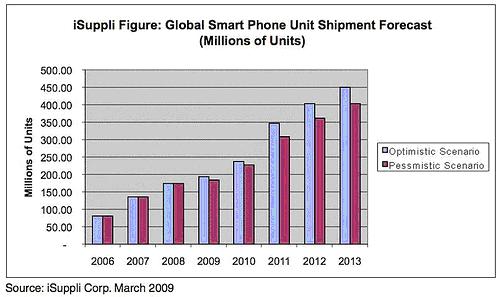
Further more, although the statistics that we found aren’t quite recent we can add that last week Apple inc. has sold 10 millions devices of its latest product, making it double than the original estimations. It would have been an even larger number but because of the major traffic that apple.com has had, the servers were down for a number of hours.
Now, in terms of data and what we are interested in, regarding the fact that all expectations were exceeded last week we can say that the only thing that is still bringing the money to Apple is the iPhone division. The sales of iPad are decreasing and so are the ones of Macs and iPods but even so the stocks listed are increasing their values. This can be explained only by following the history of the company from the day they were first listed back in the 90’s until now and observe that customer satisfaction and brand recognition as quality are one of the highest ever recorded.
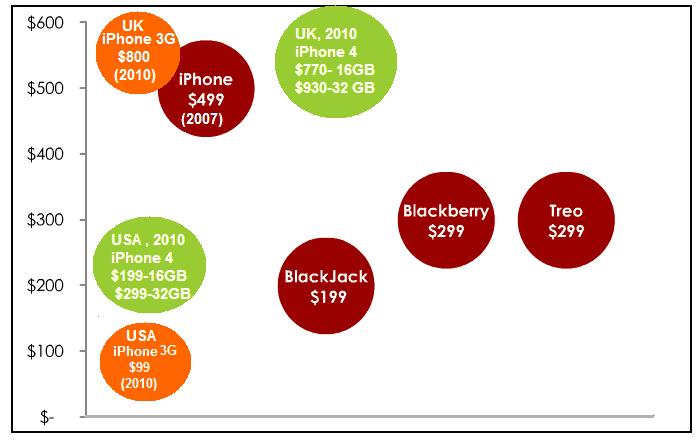
In the end i’d like to say that even if Apple took its blows first with the competitive market of Android and Windows phones, later with the death of Steve Jobs and most recently with the flaws in the iCloud system that allowed hackers to break in and publish nude pictures of dozens of celebrities, marketing data reveals that the company is still in the top preferences of gadgets enthusiasts all over the world with a consolidated position over Samsung that will not decline too soon.
Data science can be a art, a art of identifying patterns and decisions before of even being taken, all this, with impressive accuracy. For our blog’s comeback I thought I should cover more the literary part of this science-art-craft and talk about some of the ground principles exposed in some of the finest books about data science.
In today’s article I will focus on a very well sturctured paper of Trevor Hastie, Professor of Mathematical Sciences at Stanford Univesity. His book, co-writed with Robert Tibshirani and Jerome Friedman is called The Elements of Statistical Learning: Data Mining, Inference, and Prediction and tries, if not, manages to give a detailed explanation to the challenge of understanding of how data led to development of new tools in the field of statistics, and spawned new areas such as data mining, machine learning, and bioinformatics. This paper mainly observes the important fields and ideas in a common virtual framework.

The approach being mainly is statistical, the emphasis falls on concepts rather than on mathematics. Many examples are given, with a easy-to-understand use of color graphics. It is a valuable resource for statisticians and everyone interested in data mining in science or industry. The book’s coverage is broad, from supervised learning (better known as prediction) to unsupervised learning. Various topics are covered including neural networks, support vector machines, classification trees and boosting – the first comprehensive treatment of this topic in any book of this kind.
All in all I can certainly say that the presentation is not keened on mathematical aspects, and it does not provide a deep analysis of why a specific method works. Instead, it gives you some intuition about what a method is trying to do. And this is the reason why i can say that I like this book so much. Without going into mathematical details of complicated algorithms, it summarizes all necessary (and really important) things one needs to know. Sometimes you understand it after doing a lot of research in this subject and coming back to the book. Nevertheless, the authors are great statisticians and certainly know what they are talking about!
If you ever tried to use a tool for price comparison between two or more products of different online shops you definitely came in contact with the limitations that were imposed by such platforms. Usually this kind of apps work by periodically crawling a number of sites and periodically updating a certain product/price table. This is not very useful for users who want to choose products from various shops in different geographical areas or from smaller sites that haven’t been crawled by that certain app.
Now, maybe it’s a bit early to talk about the capabilities of this next product but it’s rounding up nice and can be a real help for finite consumers around the world and even for market analysts, and the best part is that it’s completely free, and with no commercials either. PriceAlert wants to be a new solution for measuring prices from various sites. Until now there’s nothing amazing but the technology behind allows users to compare prices on any ecommerce platform all over the world, because unlike other similar platforms limited to a number of well defined shops it uses an algorithm that automatically extracts data like specifications of that certain product or of course price and availability.
For now, only a beta version is available but new features are programmed to come up starting very soon. Useful proprieties like an email alert when a certain price has changed or statistics over the change in price for a period of time will be available, not to mention the capability of exporting the data gathered into various useful formats like excel or CSV.
So we think there’s no reason for you not to check out this interesting new toy and maybe leave a review in case that you feel so. You can find it here at the address //thewebminer.com/pricealert/ and we hope that together we can bring one more interesting tool to the use of people who need it.
Microformats are small patterns that can be embedded into your HTML for easier recognition and representation of common published materials, like people, events, dates or tags. Even though the content of web is fully capable of automated processing, microformats simplify the process by attaching semantics and other so lead the way for a more professional automated processing. Many advantages can be found in favor of microformats but the most crucial are these ones.
By this time i should mention that microformats are a huge relief in web scraping by defining lightweight standards for declaring info in any web page. By doing so another concept of HTML5 is defined, Microdata. This lets you define custom variables and implement certain proprieties of them.
Now that you know what microformats are we should focus on the getting started part. A really useful, quick and detailed guide can be found here, and more complex task are also available. Now, the only thing left is to wish you good luck into implementing it .