I’m coming back to writing after a short break because data science is always evolving. In this way, 2015 is promising to become a remarkable year for Big Data.
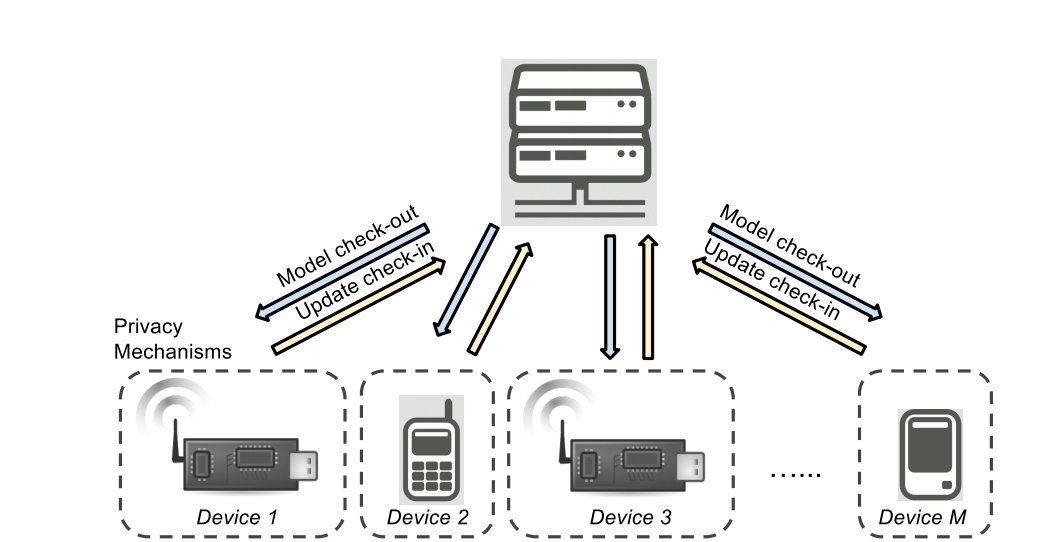
This month a new technology was introduced to public by researchers at the Ohio State University. More specific, a new privacy- preserving algorithm called Crowd-ML. This is a machine learning framework for crowdsensing systems that consists of a number of smart devices and a server. The efficiency of Crowd-ML consists in implementing sensing, learning and privacy mechanisms together, having the power to build classifiers or predictors of interest from crowdsensing data using processing capabilities of devices with formal privacy standards.
 Fig: The system learns a classifier or predictor from device generated data in online or distributed way.
Fig: The system learns a classifier or predictor from device generated data in online or distributed way.
Scalability of this technology is determined only by communication and computational loads on device and server side. By comparing these factors with the traditional centralized, crowd and decentralized learning approaches the researchers have observed a reducing of transmission time up to b/2 of the initial one.
Crowd-ML has been implemented at prototype scale on a system of three components: a web portal, normal Android smartphones and a central server and has already given a prediction error of less than 0.1 percent for activity recognition tasks.
On the same page I’d like to add that our very own product ThePriceMiner having the ability of predicting price changing rates for any ecommerce business. I’m going to end this post on a optimist note, being certain that prediction mechanisms will meet a great evolution and that we will hear again of Crowd-ML.