I want to write now about a phenomena that is a part of our lives with or without our consent. I’m talking about Apple’s market strategy and how its intrusive policy of becoming one of the most exquisite brands have affected our perception on quality or innovation.
There’s no point in denying the direct correlation between Apple total revenue and the influence it has on the market of electronics and only by looking at the graph of sales we can say so. 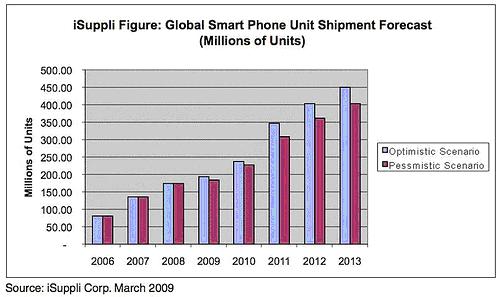
Further more, although the statistics that we found aren’t quite recent we can add that last week Apple inc. has sold 10 millions devices of its latest product, making it double than the original estimations. It would have been an even larger number but because of the major traffic that apple.com has had, the servers were down for a number of hours.
Now, in terms of data and what we are interested in, regarding the fact that all expectations were exceeded last week we can say that the only thing that is still bringing the money to Apple is the iPhone division. The sales of iPad are decreasing and so are the ones of Macs and iPods but even so the stocks listed are increasing their values. This can be explained only by following the history of the company from the day they were first listed back in the 90’s until now and observe that customer satisfaction and brand recognition as quality are one of the highest ever recorded.
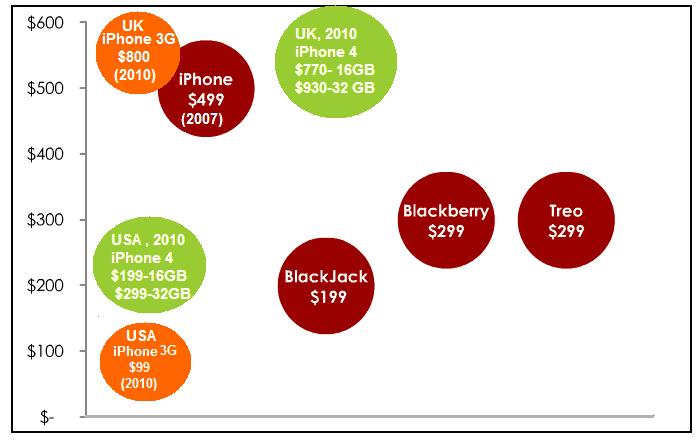
In the end i’d like to say that even if Apple took its blows first with the competitive market of Android and Windows phones, later with the death of Steve Jobs and most recently with the flaws in the iCloud system that allowed hackers to break in and publish nude pictures of dozens of celebrities, marketing data reveals that the company is still in the top preferences of gadgets enthusiasts all over the world with a consolidated position over Samsung that will not decline too soon.