
open data day
Mai multe detalii aici.
Accesati aceasta pagina pentru inscrieri la hackathon.
La TheWebMiner avem deseori nevoie să procesam fișiere text foarte mari. Când spun foarte mari mă refer la fișiere mai mari de câteva sute de megabytes. Dintre toate editoarele care le-am testat până acum cel mai mine s-a descurcat Vim, respectiv gVim (versiunea de windows a faimosului editor).
Tot pentru procesarea fișierelor text folosim și expresii regulate (numite și RegEx). Expresii care ne ajută să căutăm (sau să căutăm și să înlocuim) porțiuni de text, care respecta un anumit format, într-om mod automat. Totul este frumos până ne lovim de următoarea problemă:
Vim are un format propriu pentru expresiile regulate așa că nu putem folosi expresii regulate standard în Vim, însă noi am creat un convertor special pentru asta. Convertorul îl puteți găsi aici: //thewebminer.com/regex-to-vim.
Sperăm să vă fie de folos acest articol.
De curând am testat o unealtă de date mining despre care vreau să vă povestesc astăzi.
Aplicația se numește Datameer și este una de tip cloud bazata pe Hadoop.
Nu trebuie să instalăm nimic pe calculator, însă trebuie să avem datele pe care vrem să le analizăm.
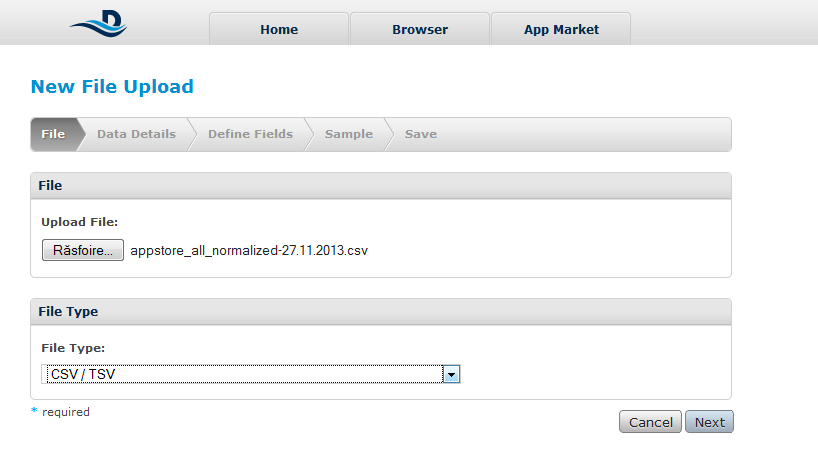
Pasul 1: Importarea datelor
Pentru a importa datele trebuie să selectam formatul în care acestea sunt reprezentate
Pasul 2: Câteva mici configurări
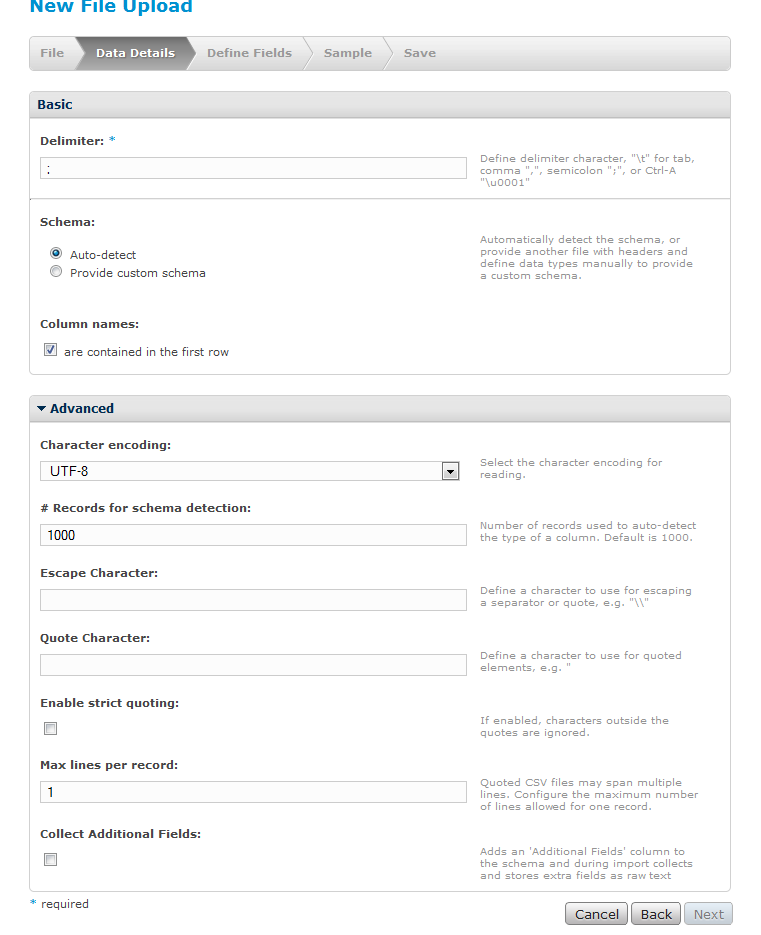
Unele dintre ele țin de formatul datelor, altele de modul de detecție a tipurilor de date. Programul încearcă să detecteze tipul fiecărei coloane. Dealtfel se pot adaugă tipurile de date dintr-un fișier.
Pasul 3: Reglaje fine
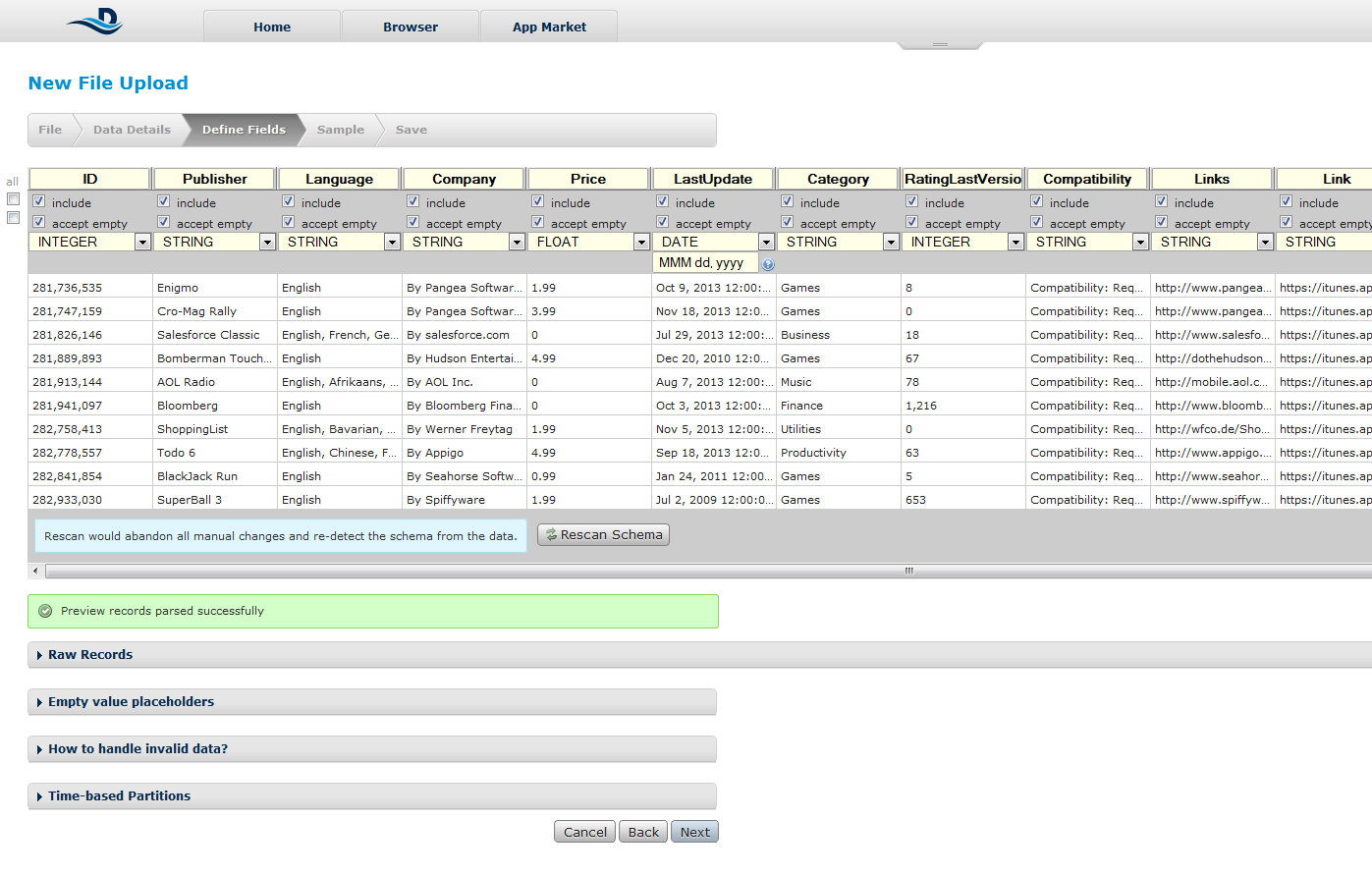
Dacă programul nu reușește să detecteze bine coloanele putem sa le introducem noi manual. Un minus al programului este reprezentat de faptul că nu putem ajusta datele în acest pas decât prin eliminarea înregistrărilor care nu corespund tipurilor de date definite de utilizator.
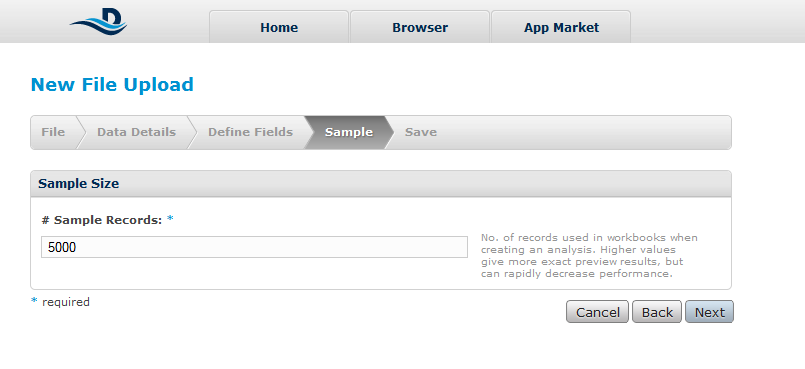
Pasul 4: Setarea eșantionului care este folosit pentru previzualizarea operațiilor
Cam ăsta a fost tot procesul prin care se adaugă datele în datameer.
Mai departe apare o interfață asemănătoare cu Excel în care vedem datele noastre.
Avem în plus câteva butoane care sunt responsabile pentru toată magia:
Column Dependency
Practic putem vedea dacă există legături între diferite coloane. Putem vedea dacă o variabilă este influențată de alta.
Clustering
Putem grupa datele după asemănarea lor.
Toată partea de descoperire a asemănărilor o face programul, noi trebuie doar sa spunem numărul de grupuri pe care vrem sa îl obținem.
Decision tree
Construiește un arbore de decizie pe baza datelor noastre.
Cam acestea sunt funcțiile magice pe care le are Datameer, dar adevărata putere a programului nu este reprezentata de funcții în sine, ci abilitatea acestuia de a le rula pe cantități uriașe de date.
De multe ori este imposibil să integrezi codul de tracking pus la dispoziție de Google Analytics și să folosești Analytics pe websiteuri care nu îți aparțin.
Motivele sunt următoarele:
1. pagina hostului nu permite inserarea codului JavaScript pentru tracking
2. nu există un feature de integrare al codului Google Analytics-ului.
Totuși, există o soluție, pentru situațiile în care poți adăuga o simplă imagine. În acest caz putem să folosim Google Analytics pentru o pagină web.

GA-Beacon – este o unealtă ce integrează Google Analytics în aplicații ce nu suportă acest serviciu.
GA-Beacon este o mică aplicație Open Source, disponibilă direct pe Github ce tratează exact problema expusă anterior. Pentru un articol complet vă recomand să citiți acest material.
Te loghezi pe Google Analytics și setezi o nouă proprietate:
1. Selectezi “Website” și folosești “Universal Analytics”.
Website name: orice nume (spre exemplu „tracking pagina profil website x”)
WebSite URL: https://ga-beacon.appspot.com/
2. Apeşi click pe “Get Tracking ID”, copiezi id-ul UA-XXXXX-X pe pagina urmatoare
Adaugi imaginea de tracking pe paginile pe care dorești să le urmărești:
Exemplu de utilizare:
https://ga-beacon.appspot.com/UA-XXXXX-X/respository/numele-paginii
UA-XXXXX-X reprezintă id-ul de tracking
/respository/numele-paginii este o cale aleasa întâmplător.
Exemplu de utilizare HTML:
<img src=”https://ga-beacon.appspot.com/UA-XXXXX-X/your-repo/page-name” />
Asta e tot! În acest moment ești gata să vezi statisticile în timp real oferite de Google Analytics pentru paginile de profil ale siteurilor. Același lucru poate fi utilizat și la mail-urile trimise pentru campaniile de promovare dar și în alte situații asemănătoare.
Articol preluat de aici: http://www.worldit.info/articole/cum-sa-integrezi-google-analytics-pe-github-e-mail-sau-pe-un-website-in-care-esti-restrictionat/
În postul precedent am vorbit despre Google Trends și cum putem să vedem trenduri de căutare. Astăzi, încercând să văd dacă există influențe vizibile asupra căutărilor de jocuri am făcut o comparație între cele două trenduri.
Ceea ce am descoperit este fenomenul de sezonalitate (vedeți în imaginea de mai jos).
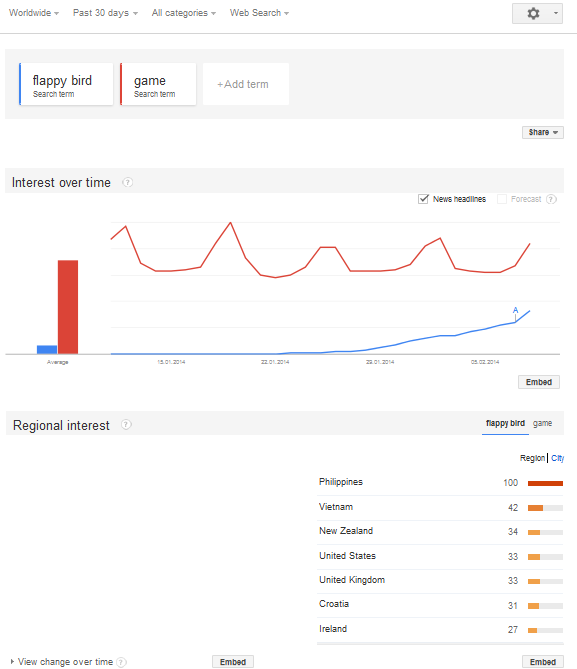
Sezonalitate
După ce m-am uitat și la date am observat că vârfurile graficului de mai sus corespund zilei de duminică. Explicaţia este evidentă.
Link: http://www.google.com/trends/explore#q=flappy%20bird%2C%20game&date=today%201-m&cmpt=q
Sunt sigur că mulți dintre voi au auzit de epidemia Flappy Bird, un joc foarte simplu lansat de curând care a reușit să crească foarte mult într-un timp scurt.
O unealtă cu care putem vizualiza trenduri de aceste fel este Google Trends
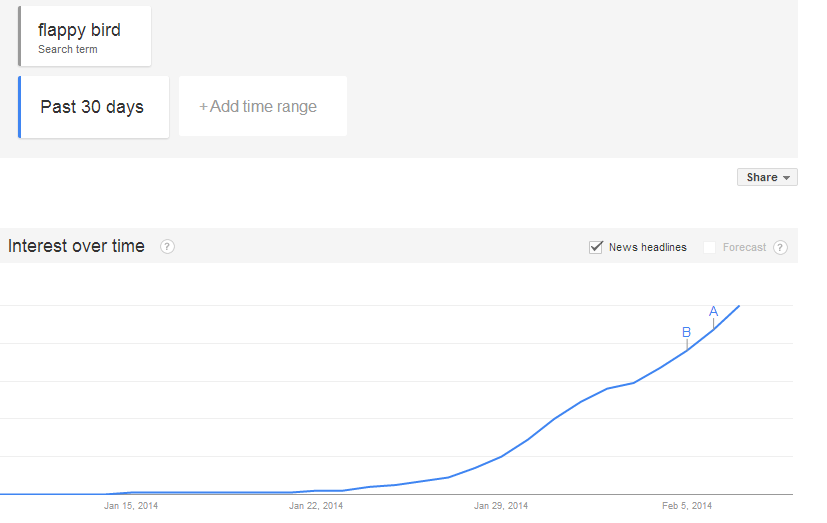
Această unealtă ne oferă câteva filtre cu care putem analiza trendul pentru o anumita zona geografica sau o anumita perioada, de altfel putem vedea și predicții.
Un alt aspect interesant este identificarea articolelor din presa ce au legătură cu trendul studiat.
Legat de Flappy Bird putem vedea că creșterea lui a început pe 27 ianuarie în insulele Filipine. Din ce a spus creatorul jocului de astăzi nu mai este disponibil și ne putem aștepta ca acest trend sa scadă, fiind acum într-un moment de maxim.
Personal cred că acest trend se va comporta precum o epidemie, iar peste câteva săptămâni va arata precum curba lui Gauss.
Inginerii de la de la Princeton au făcut un studiu privind adopția și abandonul Facebook și au ajuns la concluzia ca Facebook poate pierde 80% din utilizatori până în 2017 (adică în următorii 3 ani).
Ei au descoperit că rețelele sociale funcționează adesea ca o epidemie și au realizat un model matematic numit SIR compus din 3 componente majore ( S – susceptibil, I – infectat și R – recuperat ) .
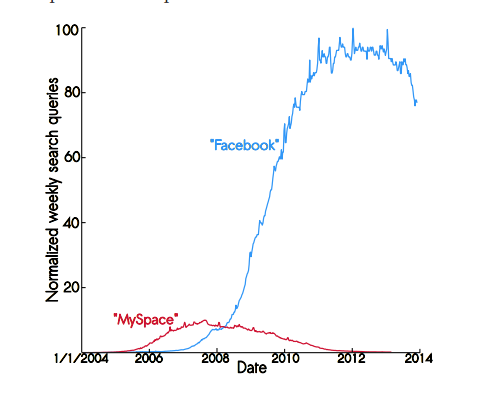
Acest model a fost validat folosind evoluția rețelei sociale MySpace:

După ce au rafinat modelul, l-au numit irSIR și l-au aplicat pentru datele disponibile despre Facebook. Ce a rezultat vedeți în imaginea de mai jos:
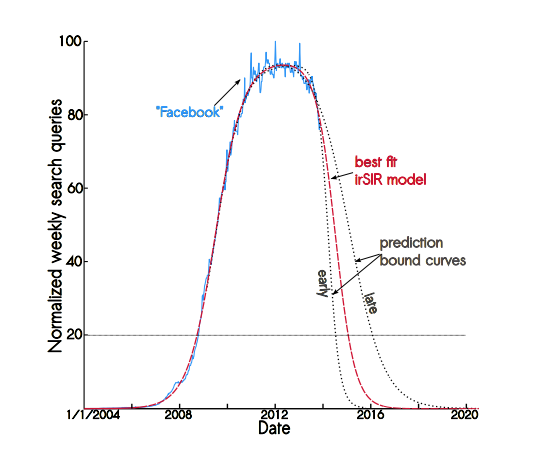
Dacă comparăm cele două rețele sociale din punct de vedere al evoluției vom constata că ambele au respectat curba lui Gauss:
Sursa: http://technorati.com/social-media/article/princeton-engineers-predict-facebook-may-lose/
Bine ați venit pe acest blog. În articolele următoare vom discuta despre Data Mining şi despre cum ne ajută acest domeniu în business, iar uneori chiar și în viață.