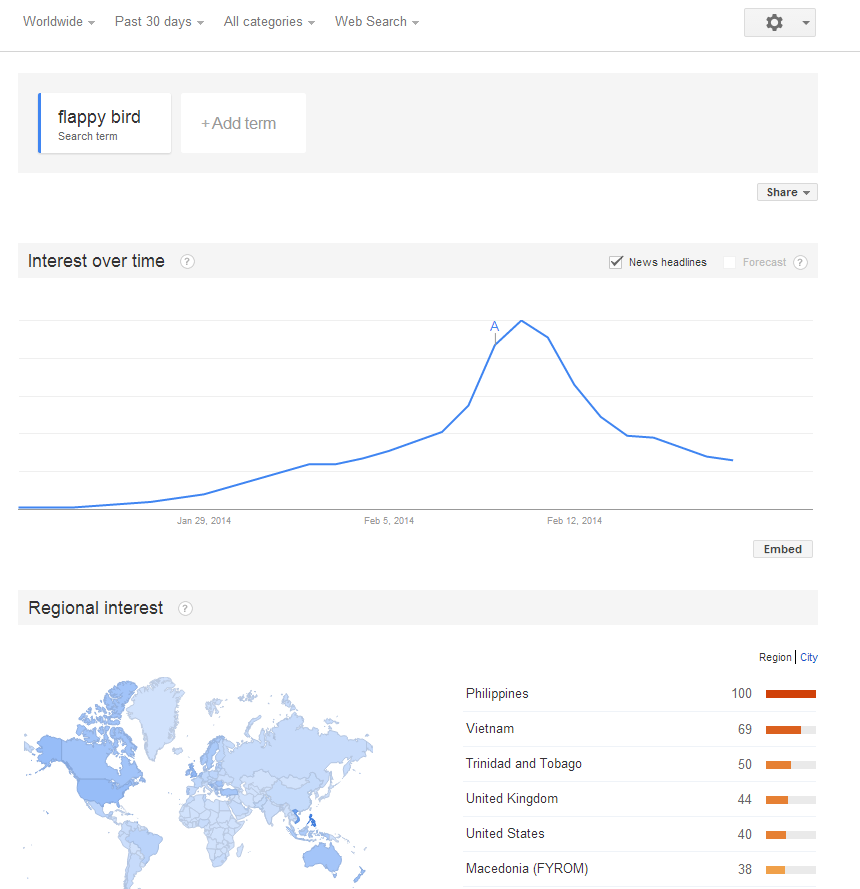
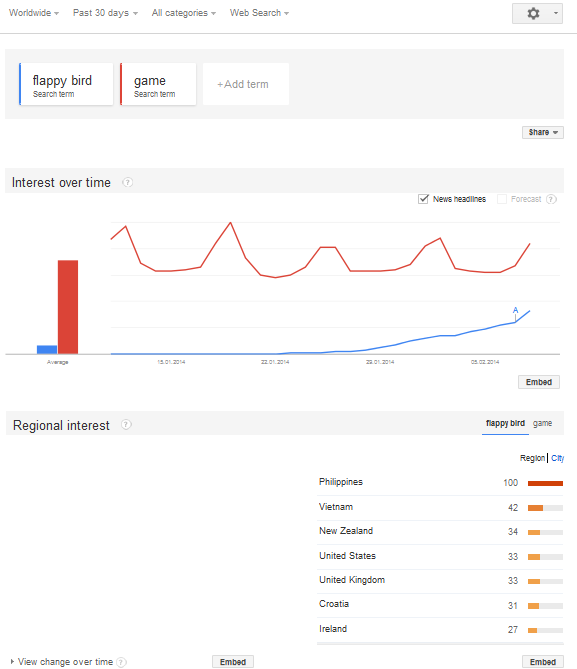
De curând am testat o unealtă de date mining despre care vreau să vă povestesc astăzi.
Aplicația se numește Datameer și este una de tip cloud bazata pe Hadoop.
Nu trebuie să instalăm nimic pe calculator, însă trebuie să avem datele pe care vrem să le analizăm.
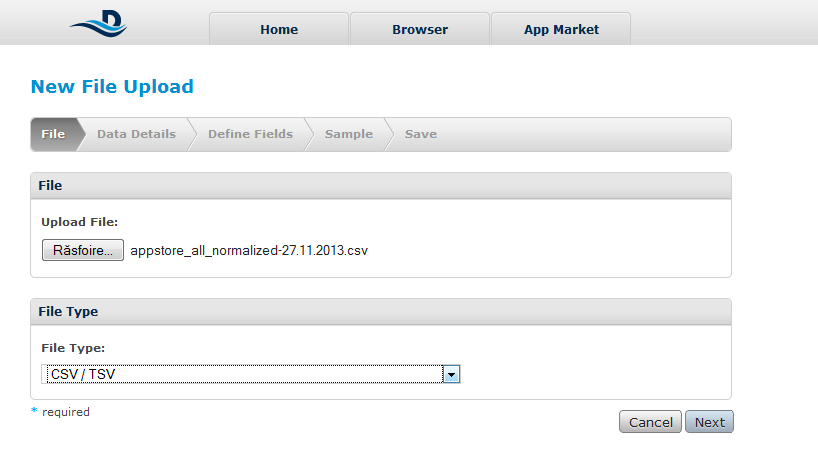
Pasul 1: Importarea datelor
Pentru a importa datele trebuie să selectam formatul în care acestea sunt reprezentate
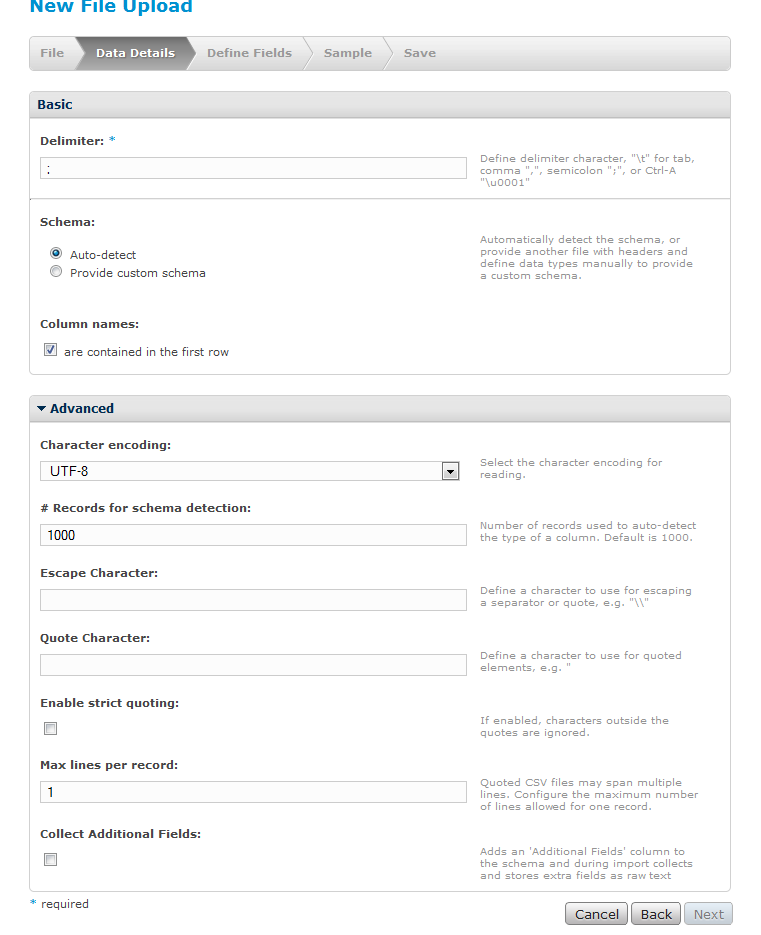
Pasul 2: Câteva mici configurări
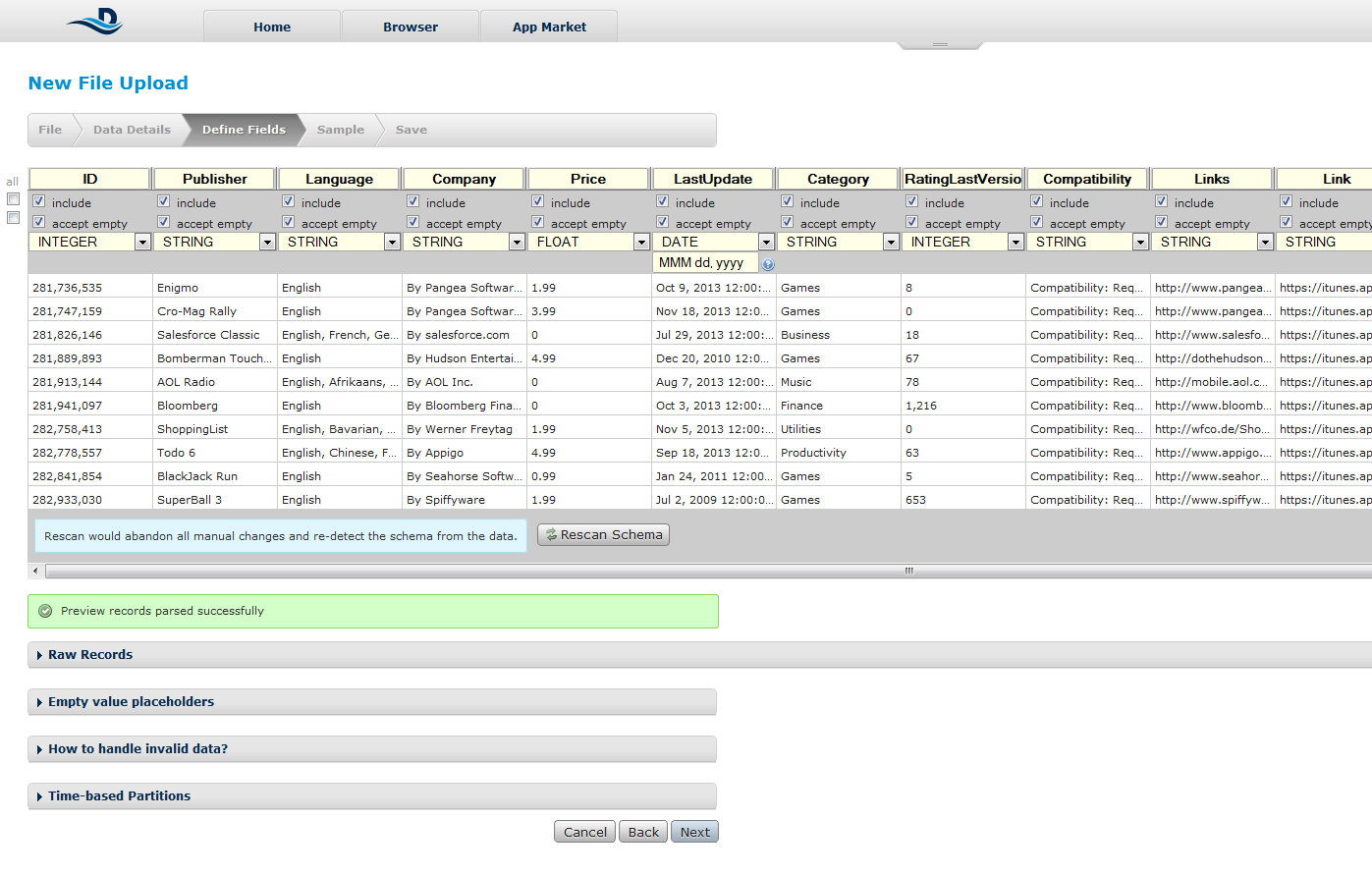
Unele dintre ele țin de formatul datelor, altele de modul de detecție a tipurilor de date. Programul încearcă să detecteze tipul fiecărei coloane. Dealtfel se pot adaugă tipurile de date dintr-un fișier.
Pasul 3: Reglaje fine
Dacă programul nu reușește să detecteze bine coloanele putem sa le introducem noi manual. Un minus al programului este reprezentat de faptul că nu putem ajusta datele în acest pas decât prin eliminarea înregistrărilor care nu corespund tipurilor de date definite de utilizator.
Pasul 4: Setarea eșantionului care este folosit pentru previzualizarea operațiilor
Cam ăsta a fost tot procesul prin care se adaugă datele în datameer.
Mai departe apare o interfață asemănătoare cu Excel în care vedem datele noastre.
Avem în plus câteva butoane care sunt responsabile pentru toată magia:
Column Dependency
Practic putem vedea dacă există legături între diferite coloane. Putem vedea dacă o variabilă este influențată de alta.
Clustering
Putem grupa datele după asemănarea lor.
Toată partea de descoperire a asemănărilor o face programul, noi trebuie doar sa spunem numărul de grupuri pe care vrem sa îl obținem.
Decision tree
Construiește un arbore de decizie pe baza datelor noastre.
Cam acestea sunt funcțiile magice pe care le are Datameer, dar adevărata putere a programului nu este reprezentata de funcții în sine, ci abilitatea acestuia de a le rula pe cantități uriașe de date.